Manuel Molina Arias
Servicio de Gastroenterología Pediátrica
Hospital Universitario La Paz. Madrid
 Dice el diccionario que una cosa es normal cuando se halla en un estado natural o que se ajusta a unas normas fijadas de antemano. Y este es su significado más normal. Pero como muchas otras palabras, normal tiene otros muchos significados. En estadística, al hablar de normal nos referimos a una distribución de probabilidad determinada, la llamada distribución normal, la famosa campana de Gauss. Esta distribución se caracteriza por su simetría alrededor de una media, que coincide con la mediana, además que otras características propias. La gran ventaja de la distribución normal es que nos permite calcular probabilidades de aparición de datos de esa distribución, lo que tiene como consecuencia la posibilidad de inferir datos de la población a partir de los obtenidos de una muestra de la misma.
Dice el diccionario que una cosa es normal cuando se halla en un estado natural o que se ajusta a unas normas fijadas de antemano. Y este es su significado más normal. Pero como muchas otras palabras, normal tiene otros muchos significados. En estadística, al hablar de normal nos referimos a una distribución de probabilidad determinada, la llamada distribución normal, la famosa campana de Gauss. Esta distribución se caracteriza por su simetría alrededor de una media, que coincide con la mediana, además que otras características propias. La gran ventaja de la distribución normal es que nos permite calcular probabilidades de aparición de datos de esa distribución, lo que tiene como consecuencia la posibilidad de inferir datos de la población a partir de los obtenidos de una muestra de la misma.
Así, prácticamente todas las pruebas paramétricas de contraste de hipótesis necesitan que los datos sigan una distribución normal. Podría pensarse que esto no es un gran problema. Si se llama normal será porque los datos biológicos suelen seguir, más o menos, esta distribución.
Craso error, muchos datos siguen una distribución que se aparta de la normalidad. Pensemos, por ejemplo, en el consumo de alcohol. Los datos no se agruparán de forma simétrica alrededor de una media. Al contrario, la distribución tendrá un sesgo positivo (hacia la derecha): habrá un número grande alrededor del cero (los abstemios o bebedores muy ocasionales) y una larga cola hacia la derecha formada por personas con un consumo más alto. La cola se prolongará mucho hacia la derecha con los valores de consumo de esas personas que se desayunan con cazalla.
¿Y en qué nos afecta para nuestros cálculos estadísticos que la variable no siga una normal? ¿Qué tenemos que hacer si los datos no son normales?
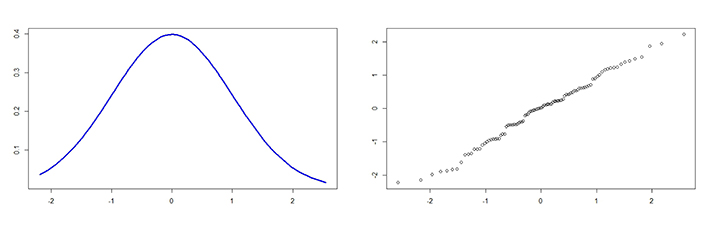
Lo primero que tenemos que hacer es darnos cuenta de que la variable no sigue una distribución normal. Existen una serie de métodos gráficos que nos permiten aproximar de forma visual si los datos siguen la normal, tal como vemos en la figura. El histograma o el diagrama de cajas (box-plot) nos permiten comprobar si la distribución está sesgada, si es demasiado plana o picuda, o si tiene valores extremos. El gráfico más específico para este fin es el de probabilidad normal (q-q plot), en el que los valores se ajustan a la línea diagonal si la distribución sigue una normal.
Otra posibilidad es emplear pruebas de contraste numéricas como la de Shapiro-Wilk o la de Kolmogorov-Smirnov. El problema de estas pruebas es que son muy sensibles al efecto del tamaño de la muestra. Si la muestra es grande pueden afectarse por desviaciones de la normalidad poco importantes. Al contrario, si la muestra es pequeña, pueden fracasar en la detección de desviaciones grandes de la normalidad. Pero es que estas pruebas, además, tienen otro inconveniente que entenderéis mejor tras un pequeño inciso.
Ya sabemos que en un contraste de hipótesis se establece una hipótesis nula que, habitualmente, dice lo contrario de lo que queremos demostrar. Así, si el valor de significación estadística es menor de valor definido (habitualmente 0,05), rechazamos la hipótesis nula y nos quedamos con la alternativa, que dirá precisamente lo que queremos demostrar. El problema es que la hipótesis nula es solo falsable, nunca podemos decir que sea verdadera. Simplemente, si la significación estadística es alta, no podremos rechazar que sea falsa, pero eso no quiere tampoco decir que sea cierta. Puede ocurrir que el estudio no tenga potencia suficiente para descartar una hipótesis nula que, en realidad, es falsa.
Pues bien, da la casualidad de que los contrastes de normalidad están planteados con una hipótesis nula que dice que los datos siguen una normal. Por eso, si la significación es pequeña, podremos descartarla y decir que los datos no son normales. Pero si la significación es alta, simplemente no podremos rechazarla y diremos que no tenemos capacidad para decir que los datos no siguen una normal, lo que no es lo mismo que poder afirmar que son normales. Por estos motivos, siempre es conveniente complementar los contrastes numéricos con algún método gráfico para comprobar la normalidad de la variable.
Una vez que sabemos que los datos no son normales, tendremos que tenerlo en cuenta a la hora de describirlos. Si la distribución es muy sesgada no podremos utilizar la media como medida de centralización y tendremos que recurrir a otros estimadores robustos, como la mediana o el otro abanico de medias disponibles para estas situaciones.
Además, la ausencia de normalidad puede desaconsejar el uso de pruebas paramétricas de contraste. La prueba de la t de Student o el análisis de la varianza (ANOVA) precisan que la distribución sea normal. La t de Student es bastante robusta en este sentido, de forma que si la muestra es grande (n > 80) puede emplearse con cierta seguridad. Pero si la muestra es pequeña o la distribución se aparta mucho de la normal, no podremos utilizar pruebas paramétricas de contraste.
Una de las posibles soluciones a este problema sería intentar una transformación de los datos. La más frecuentemente empleada en biología es la transformación logarítmica, muy útil para aproximar a una normal aquellas distribuciones con sesgo positivo (hacia la derecha). No hay que olvidar deshacer la transformación de los datos una vez realizado el contraste con la prueba en cuestión.
La otra posibilidad es emplear pruebas no paramétricas, que no precisan de ninguna asunción sobre la distribución de la variable. Así, para comparar dos medias de datos no pareados emplearemos el test de la suma de rangos de Wilcoxon (también llamado test de la U de Mann-Whitney). Si los datos son pareados habrá que usar el test de los signos de los rangos de Wilcoxon. En caso de comparaciones de varias medias, el test de Kruskal-Wallis será el equivalente no paramétrico de la ANOVA. Por último, comentar que el equivalente no paramétrico del coeficiente de correlación de Pearson es el coeficiente de correlación de Spearman.
El problema de las pruebas no paramétricas es que son más exigentes para conseguir significación estadística que sus equivalentes paramétricos, pero deben emplearse en cuanto haya la menor duda sobre la normalidad de la variable que estemos contrastando.
Y aquí lo vamos a dejar por hoy. Podríamos hablar de una tercera posibilidad de enfrentarnos a una variable no normal, mucho más exótica que las mencionadas. Se trata de la utilización de técnicas de remuestreo como el bootstrapping, que consiste en hacer una distribución empírica de las medias de muchas muestras extraídas de nuestros datos para poder hacer inferencias con los resultados obtenidos, conservando así las unidades originales de la variable y evitando el vaivén de las técnicas de trasformación de datos. Pero esa es otra historia…
Bibliografía
1.- Healy MJR. Non-normal data. Arch Dis Child.1994;70:158-63. (PubMed).
2.- Sainani KL. Dealing with non-normal data. PMR.2012;4:1001-6. (PubMed).



Cordial saludo,
luego de haber leído su texto, me genera una pregunta ¿qué ejemplos existen de datos que no siguen una distribución normal?
Le agradezco me respondiera otros ejemplos a parte de aquellos datos que provienen del azar.
Gracias
Muchas Gracias por la explicación, es la primera vez desde que empece en esto que leo una explicación tan clara, tan consista y tan precisa,y tan facilmente entendible. nunca habia entendido esto mejor que hoy.
Estimados colegas,
Me topé con vuestro artículo porque necesito resolver una cuestión. Aprovecho a consultarles lo siguiente. Necesito realizar un analisis de varianza de dos factores, pero mis datos no cumplen supuestos de normalidad, ¿existe alguna alternativa no parametrica para el análisis de varianza de dos o más factores? Gracias!